
Dialogare in modo avanzato con un LLM locale con n8n
Dialogare in modo avanzato con un LLM locale con n8n
In questo articolo vedremo le basi di utilizzo di n8n e come creare un rudimentale sistema di chat con Ollama, ne approfitterò inoltre per mostrarti perché è interessate usare n8n in congiunzione con un LLM locale.
0. Premesse
Ti ho già parlato di n8n in questo articolo per cui, qui, non mi ripeto.
Oggi infine non ti spiego come è possibile installare n8n (è mia intenzione parlartene con calma in un futuro articolo se c'è interesse).
Quest’articolo può essere usato sia come guida introduttiva all’utilizzo di n8n sia per imparare a creare un sistema rudimentale di chat con un LLM (large language model ovvero modello linguistico di grandi dimensioni).
1. Creare un workflow (flusso di lavoro) in n8n
In n8n si lavora con i workflow ovvero flussi di lavoro.
Dall’interfaccia principale basta premere il tasto “Add workflow” (aggiungi flusso di lavoro), come mostrato al punto 1 dell’immagine sottostante.
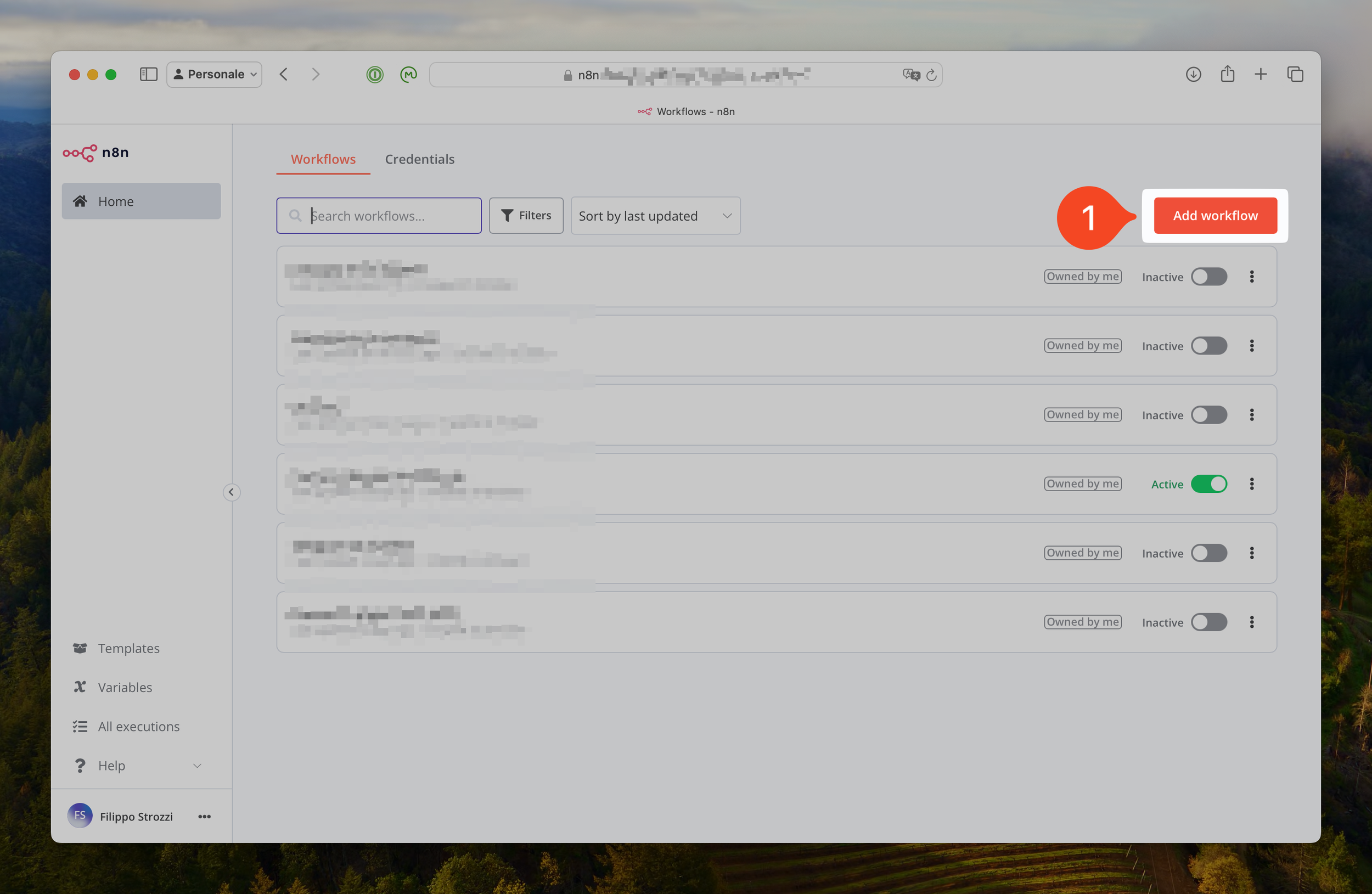
Interfaccia di n8n e pulsante per creare un nuovo workflow
2. Tutto parte da un trigger o interruttore
Non è mia intenzione esaminare in dettaglio tutti i possibili trigger disponibili in n8n. Qui occorre però sapere che un trigger è un interruttore che fa scattare il flusso di lavoro (workflow) in n8n.
Prima di fare tutto ciò, però occorre dare un nome al nostro workflow e ciò è possibile farlo andando a modificare il nome del workflow come mostrato al punto 1 dell’immagine sottostante.
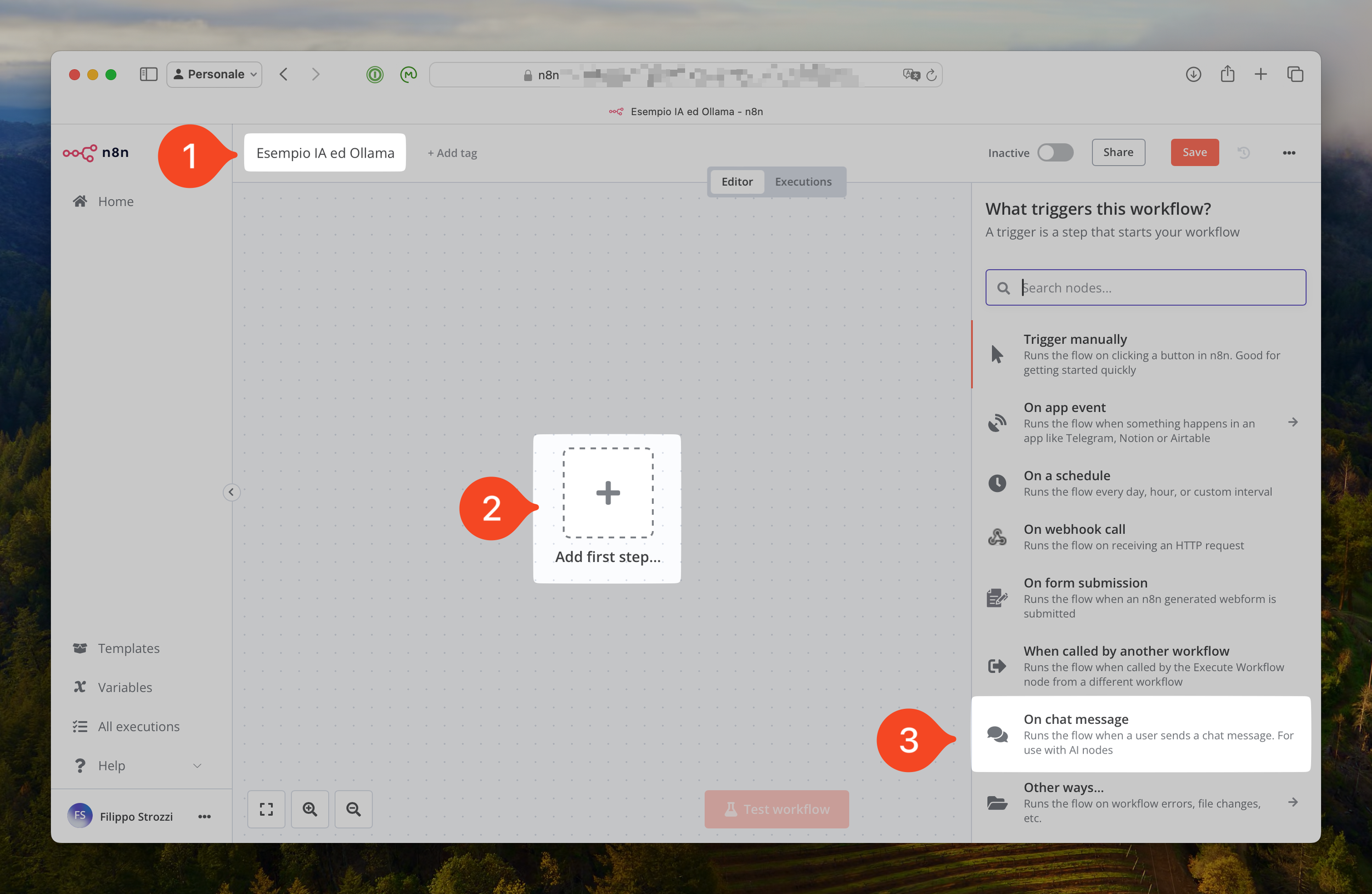
I primi passi per la creazione di un nuovo workflow
Ora siamo pronti a premere il vistoso pulsante a forma di è al centro dell’editor dei workflow sotto il quale c'è scritto “Add the first step…”, ovvero aggiungi il primo passa, come mostrato al punto 2 dell’immagine soprastante.
Per quanto riguarda gli LLM il trigger tipico è la chat, ovvero il punto 3 dell’immagine soprastante: On chat messages.
Ti voglio far notare che in n8n il menù a destra è contestuale cioè ti offre in prima battuta i nodi (o azioni) più adatte al contesto scelto.
3. Il nodo chat
Abbiamo quindi aggiunto il nostro primo nodo. n8n infatti crea flussi di lavoro (anche complessi) con una dinamica da sinistra a destra e la concatenazione di nodi, ovvero azioni che deve svolgere il workflow.
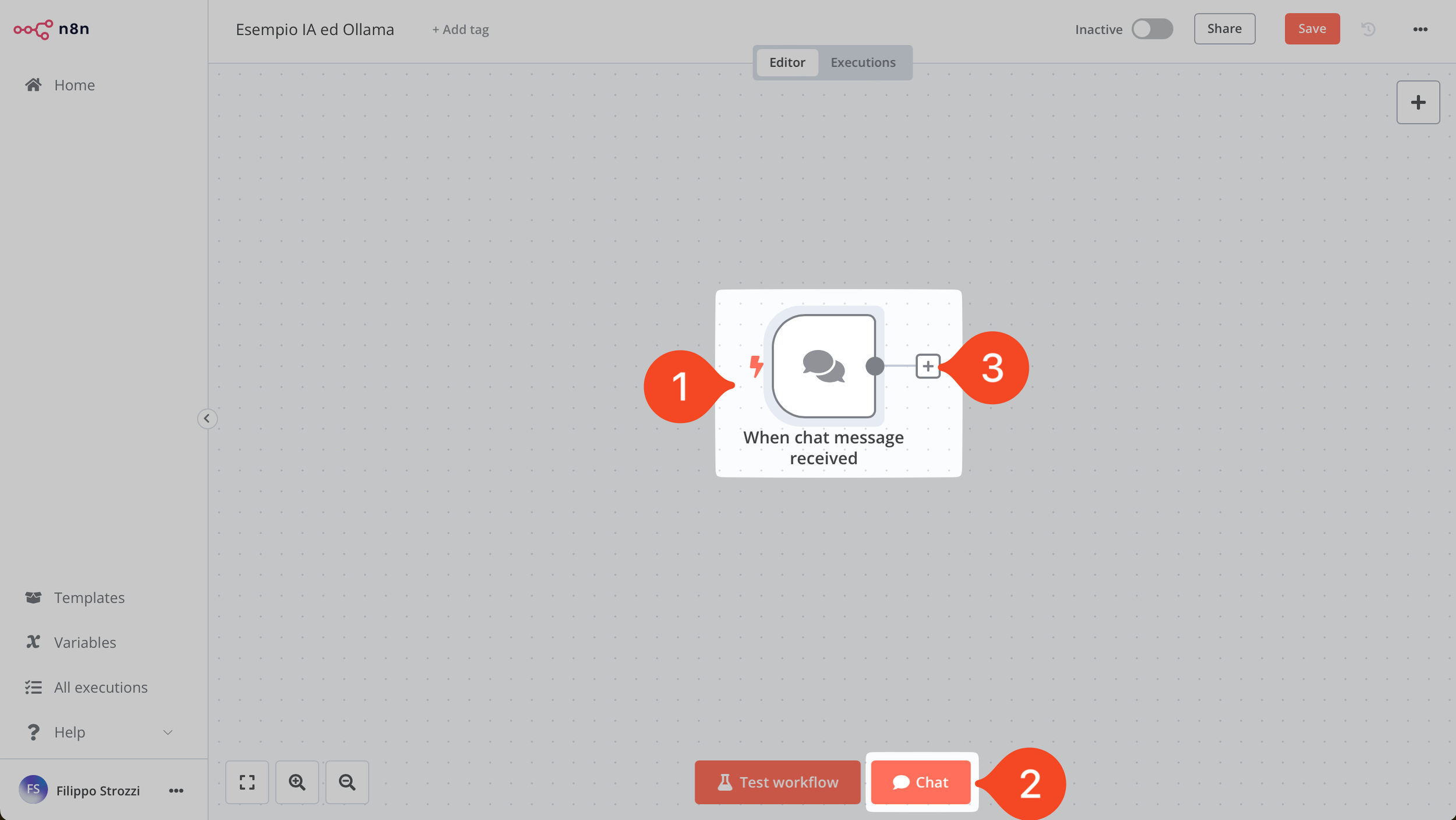
Il primo nodo: il trigger della chat per LLM
Ti troverai quindi nella situazione mostrata dall’immagine soprastante. Nota che i nodi trigger hanno accanto sul lavato sinistro un fulmine, come mostrato al punto 1 dell’immagine soprastante.
Nel caso del nodo chat, poi, nella parte bassa dello schermo compare un nuovo pulsante, come mostrato al punto 2, che ti permette di accedere alla chat.
Infine, per continuare a creare il nostro flusso di lavoro, sarà sufficiente premere il tasto + alla destra del nodo chat (ed in generale di qualsiasi nodo in n8n) come mostrato nel punto 3.
Clicca quindi sul pulsante chat e comparirà la schermata mostrata nell’immagine sottostante.
Esempio di chat in n8n
4. Intelligenza Artificiale e n8n
Come dicevo al nodo chat possiamo aggiungere diversi nodi ma il focus di questo articolo è sull’intelligenza artificiale (locale) con n8n.
Come dicevo basterà quindi premere il pulsante + a destra del nodo chat per avere il menù contestuale mostrato nell’immagine sottostante.

Esempio del menù di scelta dei nodi: in particolare i nodi Advanced AI
Scegli la voce “Advanced AI”, traducibile in IA avanzata … Sì, un po' altisonante ma, come vedremo poi, ci sono anche opzioni di utilizzo piuttosto avanzate in n8n per l’utilizzo degli LLM.
Cliccato sulla voce, ci troveremo in un sotto-menù come mostrato nell’immagine sottostante al punto 1.
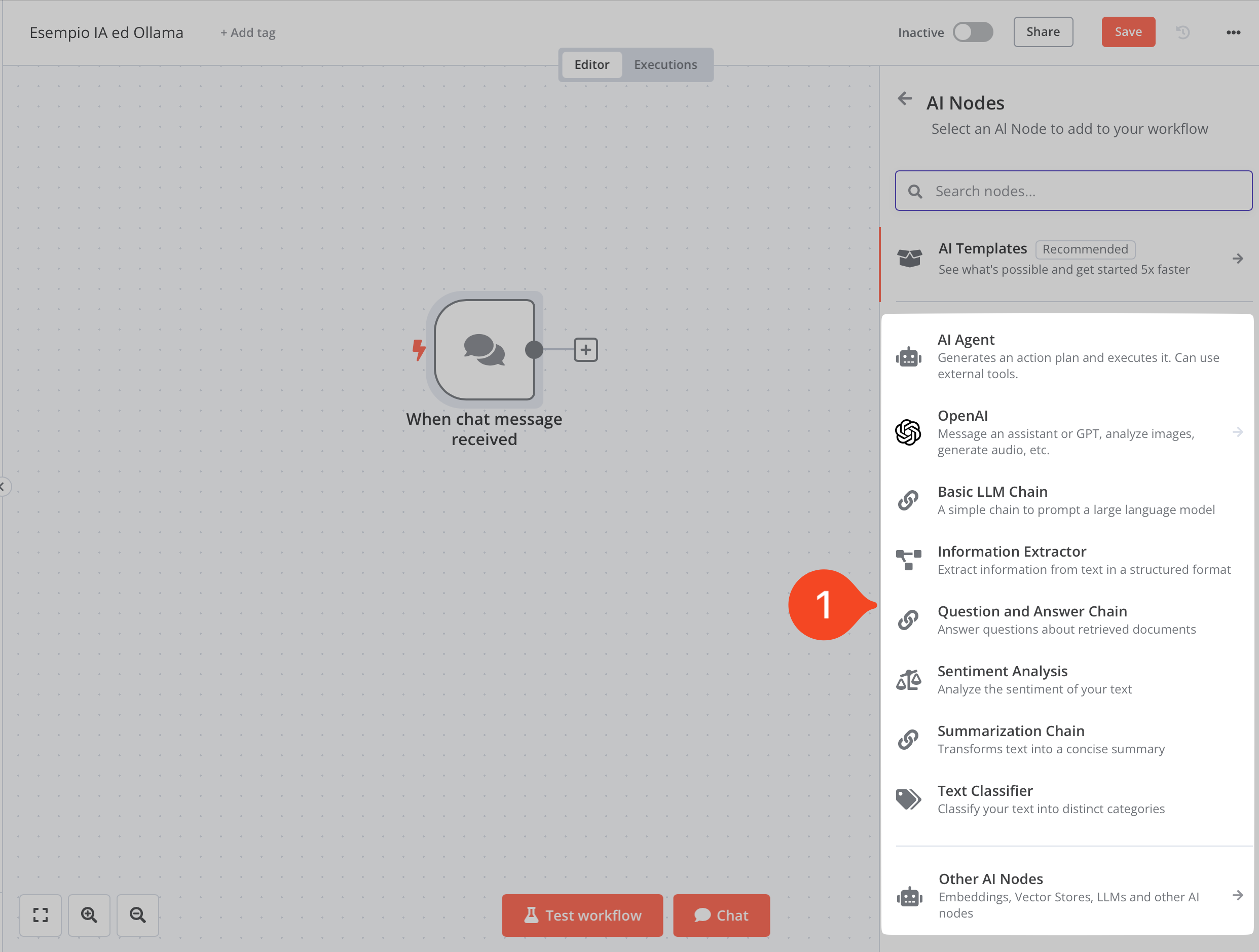
I nodi principali di n8n legati all’utilizzo della IA
4.1 I nodi “principali” per gestire l’IA in n8n
Non posso andare troppo nel dettaglio in questo articolo introduttivo ma credo sia utile fare una carrellata dei nodi “principali” presenti in n8n per la gestione delle IA.
Come si vede nell’immagine sottostante ci sono 9 opzioni:
- AI Agent: che permette di creare agenti con n8n, farò una piccolo approfondimento nei punti seguenti sull’argomento agenti;
- OpenAI: che ovviamente permette di interfacciarsi con il noto LLM online ChatGPT,
- Basic LLM chain: che permette di creare una semplice interazione con un LLM, in questo articolo vedremo questo tipo di interazione e, in successivi, quelli più avanzati;
- Information Extractor: traducibile in estrattore di informazioni che permette, nella sostanza, di estrarre dati strutturati da un testo (giusto per fare un esempio legale: i dati delle parti da un contratto);
- Questione and Answer Chain: Domanda e risposta che permette di “dialogare” con i documenti;
- Sentiment Analysis: ovvero analisi del sentimento del testo;
- Summarization Chain: traducibile in creazione di riassunto che, come dice il nome del nodo, permette di riassumere testi anche di lunghe dimensioni (superando i limiti della finestra di contenuto tipica degli LLM);
- Text Classifier: ovvero classificatore di testo che permette di classificare il testo sottoposto;
- Other AI Nodes: traducibile in Altri nodi per l’IA che permette di accedere ad altre tipologie di nodi più specifici e complementare ai nodi “principali”.

I nodi di n8n legati all’intelligenza artificiale
Come protrai aver notato, i nodi principali sono strumenti relativamente avanzati di utilizzo della IA.
Come mai n8n riesce a fare queste cose?
La risposta è semplice: utilizza sotto la scocca langchain. Langchain è un framework che permette di creare flussi di lavoro relativamente complessi con gli LLM.
4.2 Una parentesi: gli agenti
Sintetizzando, un Modello di Linguaggio di grandi dimensioni (large language model abbreviato in LLM) è un semplice sistema di auto-completamento del testo agli steroidi che fornisce il testo statisticamente più probabile a fronte di una “domanda” anche detta in gergo tecnico prompt.
La peculiarità degli LLM è che queste capacità linguistiche possono essere sfruttate per “parlare ai programmi”.
Gli agenti sono proprio questo. Un sistema che permette, attraverso l’interazione da parte dell’utente in modo testuale di eseguire programmi. Ovviamente gli agenti, per eseguire programmi, vanno “programmati” ovvero gli vanno dati gli strumenti, in gergo tecnico i tools, per interagire col mondo esterno o altri programmi.
In n8n un tool di base è la calcolatrice (Calculator) ovvero uno strumento che permette all’LLM di fare i conti correttamente (uno dei più grossi talloni di Achille dei modelli linguistici è che elaborando testo non riescono a fare di conto) oppure il nodo Wikipedia che, come dice il nome, permette all’LLM di cercare informazioni su Wikipedia.
Giusto per fare un altro esempio anche il nodo di riassunzione è, in una certa maniera, un programma a se: infatti sotto la scocca il sistema funziona istruendo LLM a suddividere un testo di grosse dimensioni in testi più piccoli per riassumerli singolarmente e, poi, una volta fatti i mini riassunti dei testi, prendere questi pezzi di riassunto e creare un ulteriore riassunto dei riassunti.
Il grosso vantaggio di questo sistema è che, per l’utente finale, i passaggi così sono trasparenti.
4.3 Gli altri nodi legati all’IA
Pur non volendo entrare troppo in dettaglio mi pare opportuno fare un breve esame degli altri nodi, giusto per permetterti di avere un quadro generale e farti capire le potenzialità di utilizzare i modelli di linguaggio di grandi dimensioni con n8n.
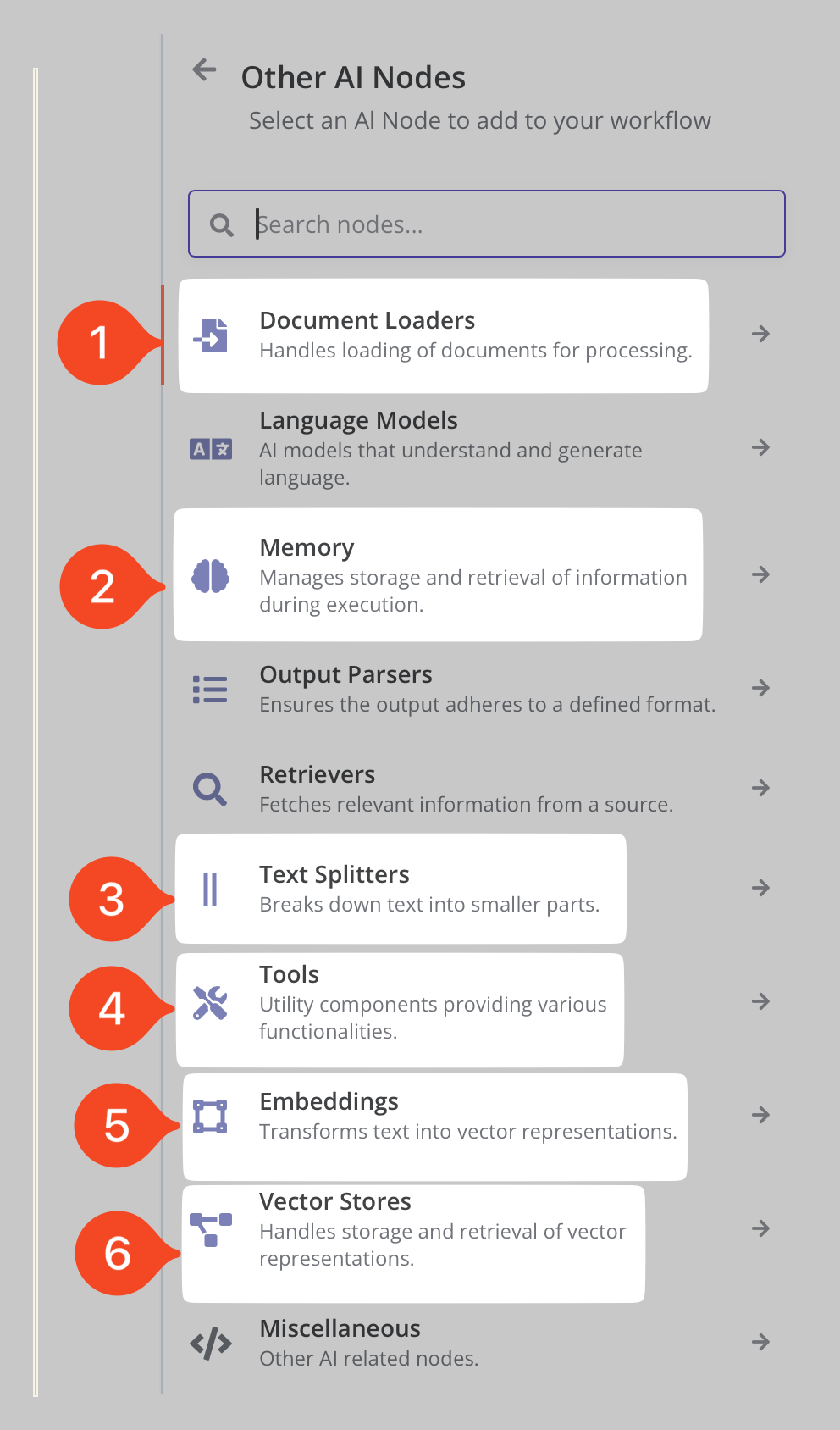
Esempio degli altri nodi IA di n8n
Mi soffermerò velocemente solo su alcuni nodi, come mostrato nell’immagine soprastante.
- Document Loaders: ovvero caricamento documenti, questo menù porta alle varie opzioni per passare i documenti ad un LLM e quindi fare delle RAG (Retrived Aumented Generation) ovvero “dialogare con i documenti”;
- Memory: ovvero memoria qui sono contenuti i nodi che gestiscono il salvataggio ed utilizzo di testo per dare una sorta di memoria agli LLM;
- Text Splitters: ovvero suddivisione del testo, questi nodi permettono, in vari modi, di suddividere testi di grosse dimensioni in c.d. chunck ovvero bocconi per renderli “digeribili” dagli LLM nella loro finestra di contenuto;
- Tools: ovvero attrezzi sono i nodi pre-pronti (è possibile crearne di propri in n8n ma è un argomento avanzato che merita un articolo a parte) per dare degli strumenti di lavoro agli LLM;
- Embeddings: sono nodi che permettono di trasformare il testo in vettori e, una volta trasformato il testo, eseguire confronti da poi utilizzare ad esempio nelle RAG;
- Vector Stores: ovvero i Gestori di vettori i nodi che servono per gestire il testo trasformato in vettore.
5. Creare una catena base con LLM utilizzando Ollama
Come ho già detto, oggi non è mia intenzione mettere troppa carne al fuoco, per cui mi soffermerò a spiegarti come sia possibile creare un flusso di lavoro base con n8n e gli LLM, in particolare quelli locali utilizzando Ollama.
Anzitutto, se vai a digitare nel campo di ricerca dei nodi, iniziando a scrivere Ollama usciranno i nodi relativi. Come si vede ne esistono 3: il modello base per ricevere risposte singole, il modello chat, che permette di “dialogare” con il modello ed infine la gestione degli Embedding attraverso Ollama.

Esempio dei nodi dedicata ad Ollama
5.1 La catena di base dell’LLM
Iniziamo quindi a creare il nostro primo workflow con n8n.
Dopo il modo chat, inseriamo il nodo Basic LLM Chains come mostrato nell’immagine sottostante. Questo nodo richiede un componente aggiuntivo ed infatti, nella parte destra del riquadro è mostrato un simbolo di allerta perché manca il modello. Premi quindi il tasto + sotto la voce Model come mostrato al punto 1.

Esempio di catena base per un LLM
Come già visto il menù contestuale di sinistra mostrerà le opzioni possibili e tu dovrai scegliere il modello base o quello per la chat, come mostrato nell’immagine sottostante.

Aggiungere Ollama come gestore di LLM
Una volta aggiunto il nodo di Ollama, essendo la prima volta, occorrerà configurarlo. Fai, quindi, doppio click sul nodo appena aggiunto e si aprirà il menù di configurazione come mostrato nell’immagine sottostante.

Il nodo di Ollama in dettaglio
Alcune considerazioni introduttive su n8n. Quello che viene mostrato nell’immagine soprastante è la tipica finestra di configurazione.
Nella parte di sinistra (riquadro rosso di sinistra) è visibile se presente, l’input passato al nodo e, invece, ne riquadro segnato in rosso di destra l’output del nodo. Al centro sono presente i parametri (Parameters in inglese) di configurazione ed i Settings del nodo.
Nel caso di Ollama occorre:
- scegliere le credenziali con cui collegarsi;
- una volta fatto ciò il modello da utilizzare per l’LLM
- i parametri opzionali da applicare al modello.
5.2 Credenziali di Ollama
Per impostare le credenziali occorre premere il pulsante a forma di matita (punto 1 immagine sottostante) e scegliere la voce Create New Credential (punto 2). Come si vede nell’immagine sottostante io ho già configurato le mie credenziali di base.

Esempio di come inserire le credenziali per Ollama
Un volta fatto ciò si aprirà la finestra di configurazione delle credenziali (in senso tecnico non sono vere credenziali ma i parametri per collegarsi alle API di Ollama).
Nell’immagine sottostante al punto 1 viene mostrato il percorso base di Ollama (corretta se l’installazione di n8n è fatta sul medesimo computer su cui è installato Ollama) ed i riferimenti alla documentazione di n8n (punto 2).

Impostazioni Ollama account
Nel mio caso, siccome Ollama è installato su un Mac differente da dove ho installato n8n [^1] ho inserito l’indirizzo ip del mio MacStudio (punto 1 immagine sottostante).
Io ti suggerisco di modificare, premendo sull’icona della matita, il nome delle credenziali, come mostrato nel punto 2: nel mio caso ho indicato il nome del Mac su cui è installato Ollama per una più semplice individuazione.

Esempio di personalizzazione delle credenziali di accesso ad Ollama
Una volta fatto ciò è possibile schiacciare il tasto Save (salva, punto 1 immagine sottostante) e, se tutto è andato a buon fine, verrà mostrato la scritta verde di avvenuta corretta connessione come mostrato nell’immagine qui sotto.
Premendo il pulsante rappresentato da un cestino (punto 2) è possibile cancellare le credenziali.

Salvataggio credenziali di Ollama
5.3 Scegliere il modello di LLM
Ora è possibile scegliere il modello da utilizzare. Come mostrato nell’immagine sottostante al punto 1, premendo la freccia che punta verso l’alto è possibile scegliere i tra i modelli installati in Ollama.
In questo video ho mostrato come installare Ollama ed i vari LLM.

Modelli disponibili nella mia installazione di Ollama
5.4 Scegliere le opzioni del modello
Seppur opzionale mi pare opportuno segnalarti l’importanza delle opzioni di configurazione del modello, presenti nel menù Options ed attivabili premendo il tasto Add Option (aggiungi opzione) come mostrato nell’immagine sottostante.

Le possibili opzioni di personalizzazione del modello di LLM
Qui non mi è possibile entrare nel dettaglio di tutti i parametri configurabili (se vuoi approfondire qui trovi la pagina relativa di Ollama) ma ritengo opportuno esaminare almeno alcuni parametri fondamentali.
Il primo parametro (punto 1) è la temperatura del modello (temperature). Tendenzialmente varia da 0 a 2 e più il valore è alto più il modello di linguaggio sarà “creativo” e conseguentemente soggetto ad “allucinazioni”. Questo parametro quindi va ragionato in base al compito affidato e risultato che si vuole ottenere dal modello.
Il secondo parametro (punto 2) è la finestra di contesto del modello o Context Lenght del modello. Ollama di default utilizza per tutti i modello la finestra di contesto di 2048 tokens ovvero 2k. Questa finestra è piuttosto piccola ma se non si dispone di molta vRAM è corretta. Anche qui è opportuno configurare adeguatamente la finestra di contesto in base all’hardware a disposizione e al compito che deve svolgere l’LLM. Ad esempio una grossa finestra di contesto è utile se il prompt passato al modello è di grosse dimensioni.
Ultimo accenno va al Output format ovvero al formato della risposta dell’LLM (punto 3). Abitualmente va lasciato al valore Default ma se si vuolo “forzare” la risposta in formato JSON (una struttura dati compatibile con i nodi di n8n) e se supportato dall’LLM è qui che va configurato.

Alcuni parametri opzionali di gestione del modello di LLM
5.5 Ultimazione della creazione del nostro primo flusso di lavoro
Ottimo, se ha seguito passo passo i punti che precedono, ti troverai davanti a quanto mostrato nell’immagine sottostante: il tuo workflow con IA in n8n.
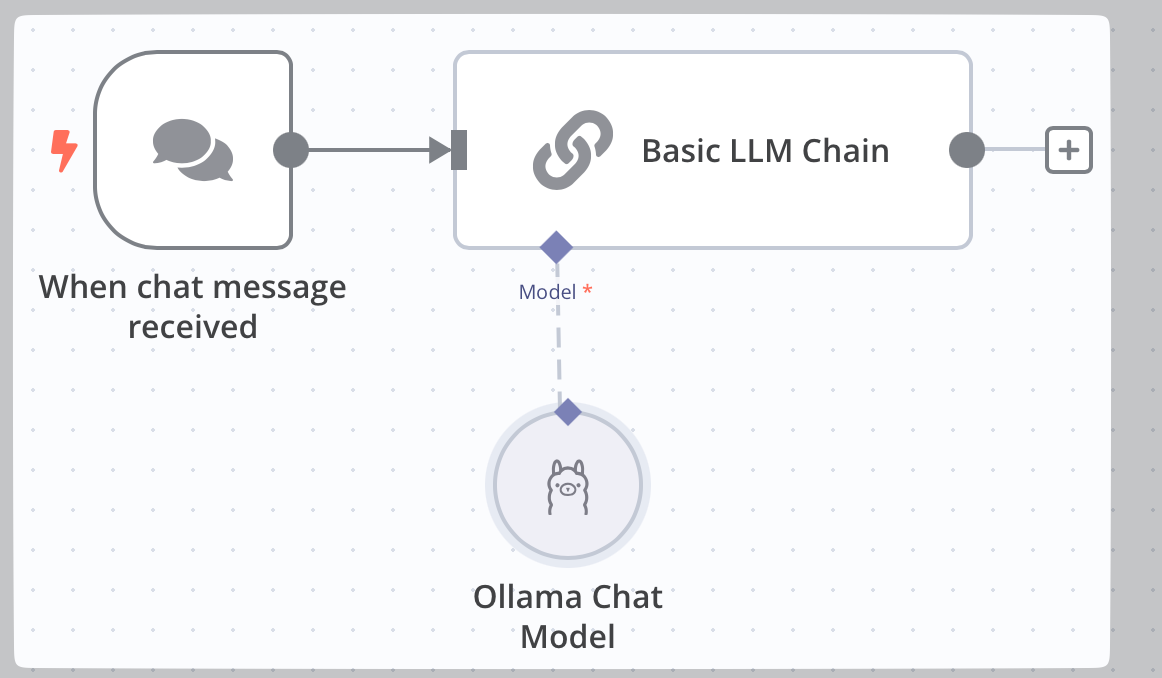
Risultato finale di workflow base con Ollama e n8n
Ora puoi premere il pulsante arancione chat e digitare una domanda nella chat come mostrato nell’immagine sottostante.

Chat con LLM: esempio
Come mostrato nell’immagine soprastante l’LLM inizierà a “pensare” la risposta.
Infine comparirà la risposta come mostrato nell’immagine qui sotto.
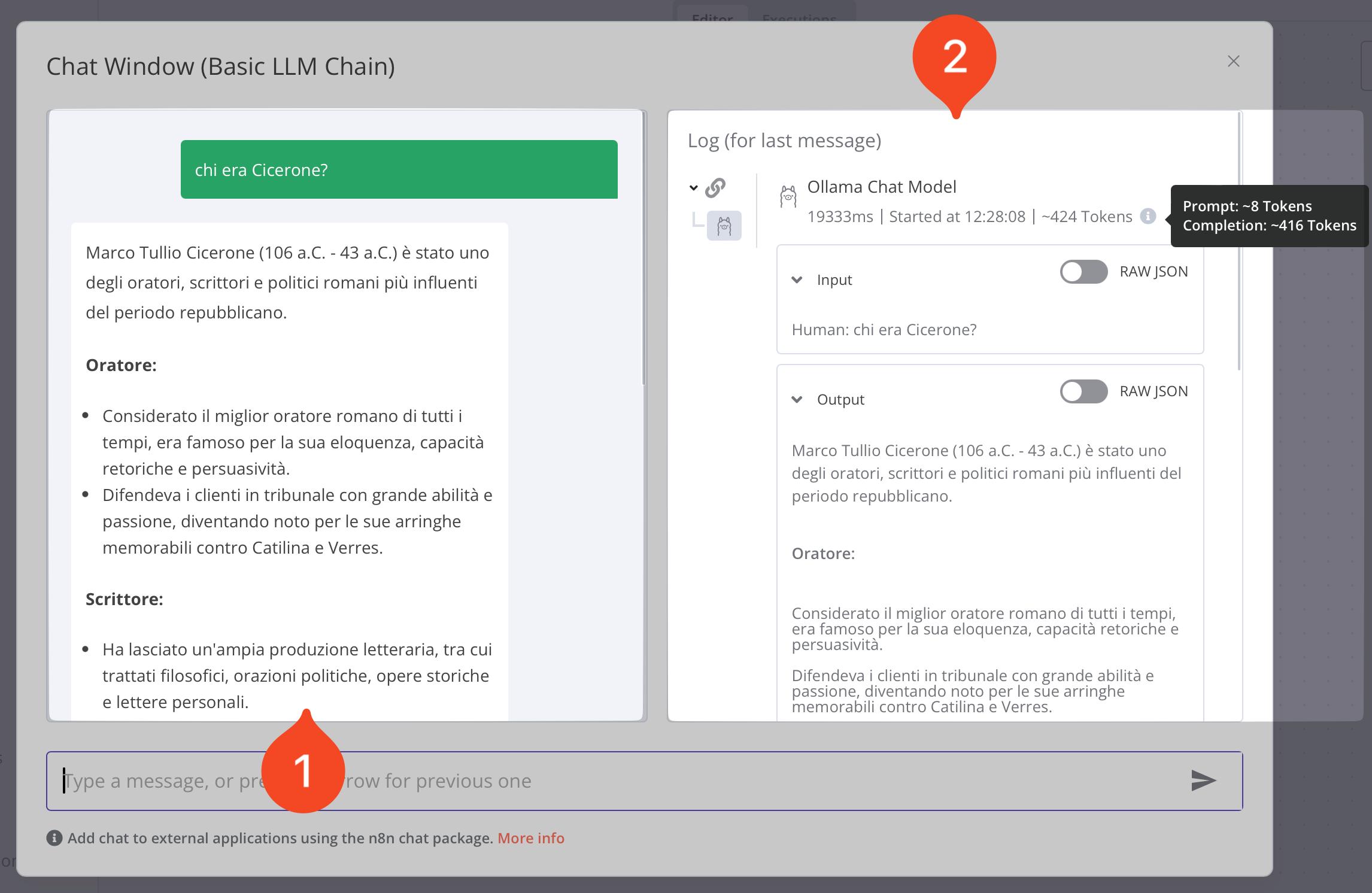
Risposta in n8n di chat con LLM
Sul lato sinistro della chat (punto 1) verrà mostrata la risposta dell’LLM mentre sul lato destro (punto 2) verranno mostrati i passaggi eseguiti dall’LLM per giungere alla risposta. Questo potrebbe sembrarti poca cosa per il workflow che abbiamo appena creato ma, per flussi di lavoro più complessi, è molto utile per vedere se il funzionamento del workflow ha rispettato quanto avevamo previsto.
Se, infine, usciamo dalla chat noteremo che il flusso di lavoro ha generato un oggetto (item), come mostrato al punto 1 dell’immagine sottostante.
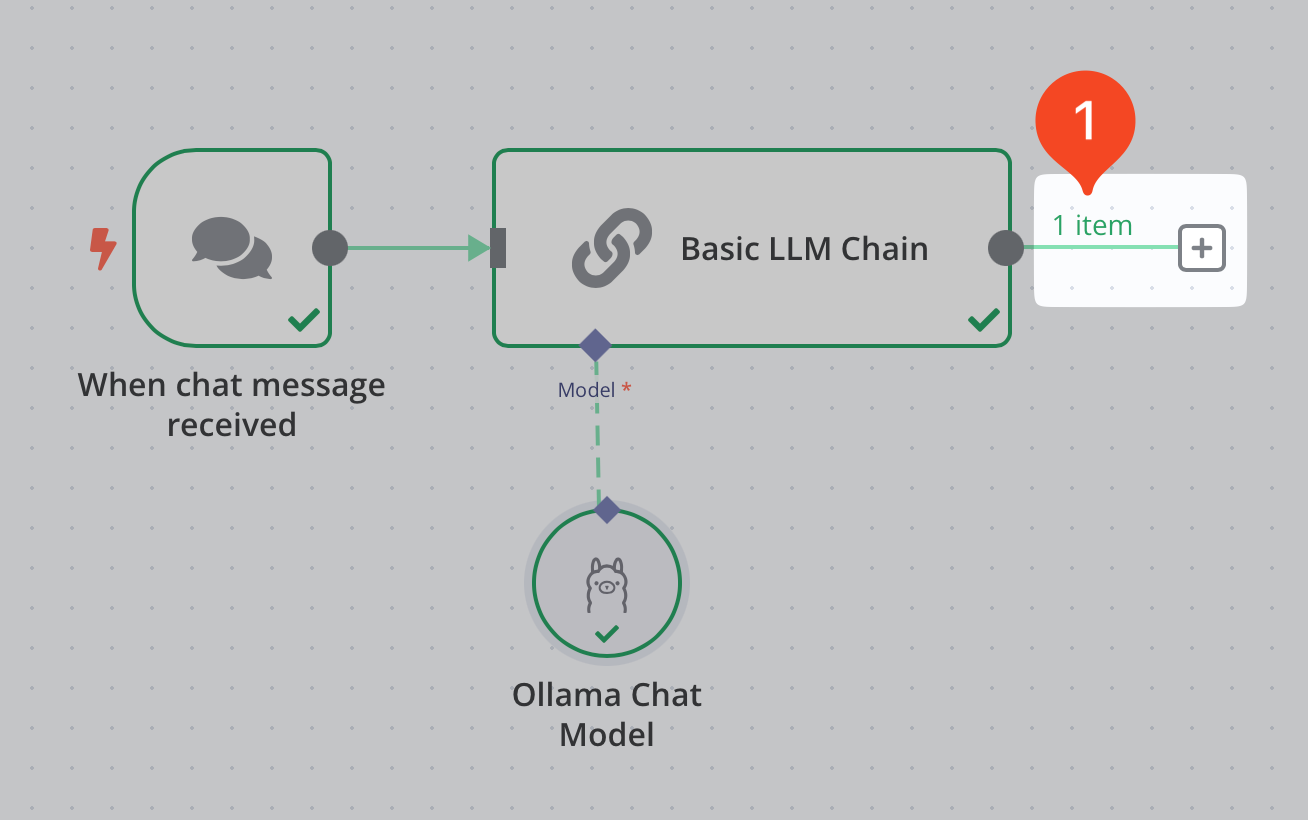
Generazione di un oggetto in n8n
Questo è il tipico comportamento di n8n: ogni nodo crea uno o più oggetto che, a loro volta, possono essere passati ad un nuovo nodo per ulteriori elaborazioni.
6. Salviamo la risposta dell’LLM
Per concludere, quindi, vediamo come salvare la risposta dell’LLM in un file RTF sul nostro Mac.
Come già visto premiamo sul tasto + alla destra del nodo Basic LLM Chains. Nel menù contestuale andiamo nella funzione ricerca e digitiamo file. Dovrebbe venir mostrata la voce Convert to File, clicchiamola e tra le opzioni scegliamo Convert to RTF (punto 1 immagine sottostante).

Esempio di salvataggio del chat come file RTF
Comparirà il nuovo nodo (punto 2), clicchiamoci sopra.
Siccome nel nodo precedente erano già presente un oggetto, il nodo Convert to File sarà popolato con svariati dati, come mostrato nell’immagine sottostante.
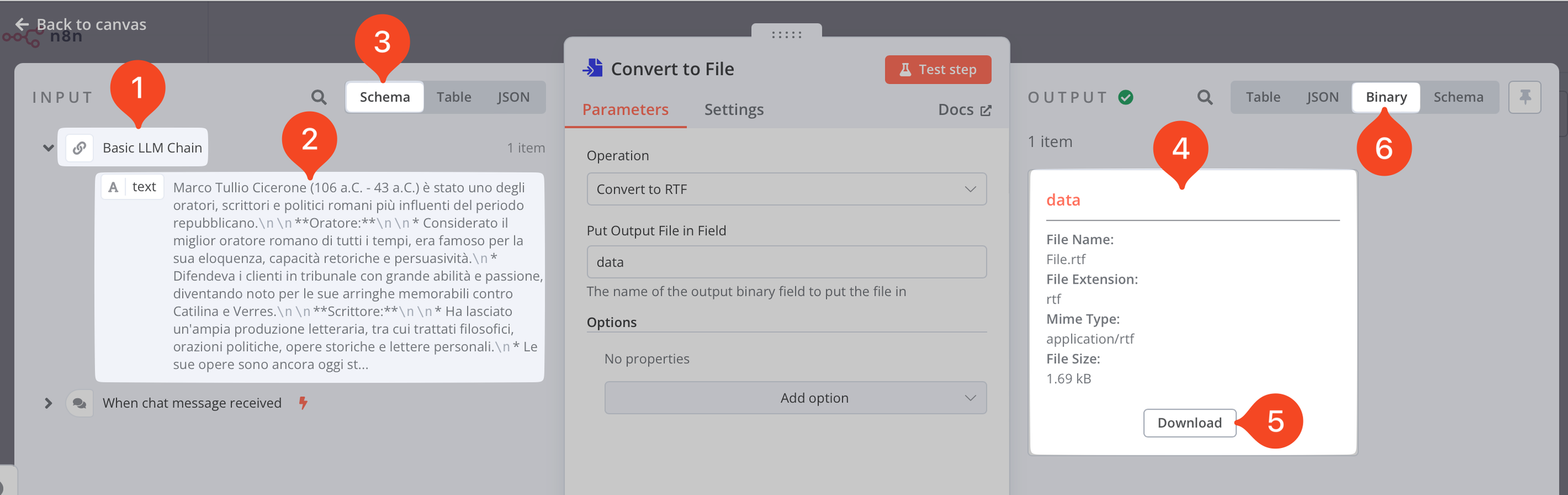
Esame del nodo Convert to File
Nella parte sinistra dedicata all’input, verrà mostrato quanto creato dai nodi precedenti (nel nostro caso solo la Basic LLM Chains) punto 1. Sotto di essa è mostrato il contenuto generato dal nodo, punto 2, e le varie modalità di visualizzazione (punto 3):
- Schema, la visualizzazione più user friendly;
- table, ovvero tabella;
- JSON, la visualizzazione testuale con dati strutturati.
Sul lato destro, una volta premuto il tasto Test Step (ovvero Testa il passaggio), mostra quale oggetto la voce Data (punto 4) con la descrizione del file, la possibilità di scaricarlo (punto 5) premendo il tasto Download e verificare l’esatta creazione del file RTF, ed infine la voce Binary (punto 6), ovvero file binario.
6.1 Salviamo il file sul nostro Mac
Siamo arrivati quasi alla fine ma questo passaggio è essenziale e, nei prossimi articoli, sarà la chiave di volta per creare flussi di lavoro locali.
Per creare una automazione efficace, infatti, occorre poter automatizzare il salvataggio dei documenti sul proprio computer.
Per vario tempo mi sono arrovellato su come fare ciò in n8n. Infatti n8n nasce per creare workflow utilizzando servizi online, come ad esempio GoogleDrive ed affini. Io, invece, non voglio che giri nulla sul cloud di altri ma solo sui miei computer.
La soluzione era banale, bastava solo trovarla!
Su macOS è possibile abilitare un server sFTP (in particolare in sFTP la “s” sta per secure ovvero sicuro) configurando l’accesso vis SSH al Mac (c.d. Login Remoto).
Fatto ciò, è possibile utilizzare il nodo FTP di n8n per salvare uno o più file in una cartella del nostro Mac. Vediamo in dettaglio come fare.
Il primo passo è quello di scegliere una cartella in cui salvare i file e copiarne il percorso (nel Finder abilitata la barra del percorso selezionale la cartella tenendo premuto ⌥ e copia, come mostrato nell’immagine sottostante, punto 1).

Esempio di salvataggio negli appunti del percorso di una cartella
Aggiungere il nodo FTP scegliendo il nodo Upload a file (carica un file).

Nodo FTP di n8n
Configura il nodo correttamente, inserendo le credenziali (punto 1 immagine sottostante), controlla che la voce Operation (operazione) sia impostata su Upload (carica file), punto 2, ed infine inserisci, nel campo Path (percorso), il percorso completo alla cartella in cui si vuole salvare il documento (quello che hai salvato negli appunti di macOS al punto precedente per intenderci), facendo attenzione ad indicare anche il nome e l’estensione del file da salvare (punto 3).

Configurazione del nodo sFTP
Di seguito mostro la configurazione delle credenziali per salvare un documento sul mio MacMini M1, ovviamente tu devi configurarle per il tuo Mac.
Per l’host occorre inserire l’indirizzo IP del Mac o il nome di dominio locale, la porta SSH (abitualmente la 22) e le credenziali: Username (nome utente) e password del Mac (alternativamente è possibile usare una Privatekey – da configurare).

Esempio di mia configurazione delle credenziali sFTP per accedere al mio MacMini M1
E con questo abbiamo finito!
In conclusione
È stata un lungo articolo ma spero di averti introdotto sia all’uso di n8n ed in particolare alle sue funzioni di automazione con i modelli di grandi dimensioni locali, grazie ad Ollama.
Quello che ti ho mostrato è un flusso di lavoro relativamente semplice (ed inutile) ma in futuri articoli vedremo come utilizzare queste basi per creare flussi di lavoro più complessi.
Come sempre, se ti è piaciuto quel che hai letto o visto e non l’hai già fatto, ti suggerisco di iscriverti alla mia newsletter. Ti avvertirò dei nuovi articoli che pubblico (oltre ai podcast e video su YouTube) e, mensilmente, ti segnalerò articoli che ho raccolto nel corso del mese ed ho ritenuto interessanti.
[^1]: A dir il vero n8n non è installato su un Mac ma su una macchina virtuale del mio server Proxmox … ma questa è un’altra storia!