
OCR gratuito con Tesseract e Keyboard Maestro
L'articolo di oggi è un’anticipazione di quello che spero sarà un video articolo che ho in programma di pubblicare.
Di fatto ho creato l’automazione di cui vi parlerò oggi per risolvere alcune limitazioni della soluzione open-source e gratuita che ho implementato per fare l'OCR (Riconoscimento ottico dei caratteri) dei PDF.
1. Soluzioni gratuite e soluzioni a pagamento: l’utilità dell'OCR
Io sono un fermo sostenitore dell'acquisto di software professionali per l’attività lavorativa di un professionista. Tuttavia mi rendo conto che molti non sono in grado / vogliono affrontare queste spese. Giusto per darvi un'idea io spendo circo € 250 per l’abbonamento annuale di Adobe Acrobat Pro DC. Lo ritengo una spesa più che giustificata perchè, quando ho bisogno di svolgere operazioni “complesse”, ce l'ho a disposizione anche se, nell’80 % dei casi, utilizzo Anteprima per la gestione quotidiana dei PDF su macOS.
Molti colleghi però non condividono la mia visione tecnologica e “spendacciona” per il software.
L’OCR è uno strumento necessario ed utile per la gestione dell’ufficio digitale, ne ho parlato più dettagliatamente in questo articolo tempo addietro, inoltre il riconoscimento ottico dei caratteri nei documenti allegati ai depositi telematici è una delle condizioni per vedersi riconosciuto la maggiorazione del 30 % sul compenso professionale giudiziale. Infatti i documenti allegati devo essere ricercabili, ovvero, il testo contenuto al loro interno non deve essere una mera immagine ma anche possedere un livello (nascosto) di testo identico a quello dell'immagine del documento.
Come ho anche spiegato nel mio webinar dedicato alla digitalizzazione dello studio legale / professionale io implemento anche un sistema di digitalizzazione con OCR immediato attraverso l'acquisizione dei documenti cartacei con lo ScanSnap iX500 della Fujitsu (ora c'è il modello iX1500).
Ciò detto, so benissimo di non poter convincere tutti con le mie argomentazioni e, negli ultimi mesi, mi sono alambiccato su come far provare agli indecisi le potenzialità dell’OCR senza “impegno” (economico).
Ho così scoperto il progetto open-source Tesseract.
2. Pregi e difetti di Tesseract
Tesseract) è un software originariamente sviluppato da Hewlett-Packard e poi il codice è stato reso pubblico. Il software è un sistema di OCR a riga di comando ovvero è possibile indicare a Tesseract una o più immagini su cui fare l'OCR e ricevere in ritorno il testo riconosciuto o, meglio ancora, un PDF con l'immagine passate e, all’interno di un livello nascosto, il testo riconosciuto. Possiede dizionari di riconoscimento per varie lingue, tra cui l'italiano, e dalla mia esperienza personale i risultati di riconoscimento sono buoni (a patto di passare immagini con una buona risoluzione e sufficientemente contrastati). Inoltre, essendo open-source, è presente su tutte le piattaforme Mac, Windows e Linux.
Le limitazioni principali di Tesseract, quindi, sono:
- la necessità di passare una o più immagini per svolgere l’OCR, non è quindi possibile passare semplicemente un PDF;
- non c’è un’interfaccia grafica ma funziona esclusivamente a riga di comando.
Come sempre tuttavia le limitazioni possono essere aggirate con un po' … di automazione!
È nata così la macro di Keyboard Maestro di cui vi voglio parlare oggi.
3. Installazione di Tesseract
Prima di vedere la macro tuttavia occore installare sul Mac (ma è possibile farlo anche su Windows e Linux).
Come sempre utilizzeremo Homebrew per l’installazione. Qui trovate la guida che ho scritto su come installare Homebrew sul di un Mac.
Do quindi per scontato che abbiate Homebre installato sul vostro Mac. Aprite il Terminale e digitate il seguente comando:
brew install tesseract tesseract-langLa stringa “tesseract-lang” è fondamentale perchè scaricherà i vari dizionari di riconscimento delle lingue, in particolare di quella italiana.
4. Rapido esempio di come funziona Tesseract
Di seguito vi lascio un esempio (molto banale) di elaborazione a riga di comando:
tesseract input.tiff test -l ita pdf“Tesseract” è il comando, “input.tiff” è il file immagine da cui riconoscere il testo e fare l’OCR, “test” è il nome del documento convertito, “-l ita” è l'opzione di scelta della lingua in italiano ed infine “pdf” è il tipo di file in cui viene convertito il documento finale
5. Convertire i PDF immagine in TIFF multipagina
Il trucco per semplificare le operazioni con Tesseract, ovvero evitare di convertire un PDF multipagina in singole pagine e poi passarle una alla volta o con uno script in Tesseract, è quello di convertire il PDF in un file TIFF multipagina. Il formato TIFF è l'unico che permette di avere immagini su più pagine.
Grazie ad Anteprima, poi, è possibile convertire facilmente un PDF multipagina in un file TIFF multipagina. Non sto a spiegarvi in dettaglio perché non useremo questo metodo, sappiate che è possibile se volete utilizzare tutto senza automazioni (io ho iniziato così).
6. L’automazione con Keyboard Maestro
Con poca fantasia ho riciclato, modificandola, l'automazione che avevo usato in questo ed in questo articolo. Di fatto la macro è relativamente semplice … prendende il PDF senza OCR selezionato nel Finder e lo converte in TIFF multi-pagina e poi passa questo file a Tesseract che ne fa l'OCR e genera un PDF multi livello con l’originale scansione ed il livello nascosto di testo estratto dall’immagine attraverso l’OCR. Infine cancella il file TIFF che, oltre a non servirci più, occupa molto spazio sul disco fisso.

Macro di Keyboard Maestro
Non mi dilungherò molto nella descrizione della macro perché l'ho già dettagliata negli articoli precedenti, mi soffermerò semplicemente sulle “particolarità”.
6.1 Alcuni dettagli della macro
Anzitutto per far funzionare la macro con un file intermedio ho dovuto aggiungere una nuova variabile con il percorso del file TIFF (che prende il nome ed il percorso del documento selezionato da noi nel Finder).

La variable per il file TIFF intermedio
Ho quindi impostato questa variabile all’interno del comando sipsche converte il PDF in una file TIFF (prima riga dell’azione Execute Shell Script – immagine sottostante).
Successivamente eseguito sul file TIFF l'OCR con Tesseract usando il comando che ho descritto nella parte iniziale dell’articolo (seconda riga dell’azione Execute Shell Script – immagine sottostante).

Lo script per la conversione in TIFF multipagina ed il seguente OCR
Non ho approfondito molto la tematica di Sips (per chi è interessato ho lasciato alcuni riferimenti nel materiale di riferimento a fine articolo).

Pagina del manuale (man) di Sips
Ho semplicemente riciclato il semplice comando:
sips -s format tiff input.pdf --out output.tiffe sostituendo ai file di input e di output i percorsi creati dalla serie di azioni della macro di Keyboard Maestro.
Da ultimo ho aggiunto due azioni per cancellare il file TIFF e dalla cartella.
La prima azione attende un secondo per assicurarsi che l'opzione di OCR del TIFF
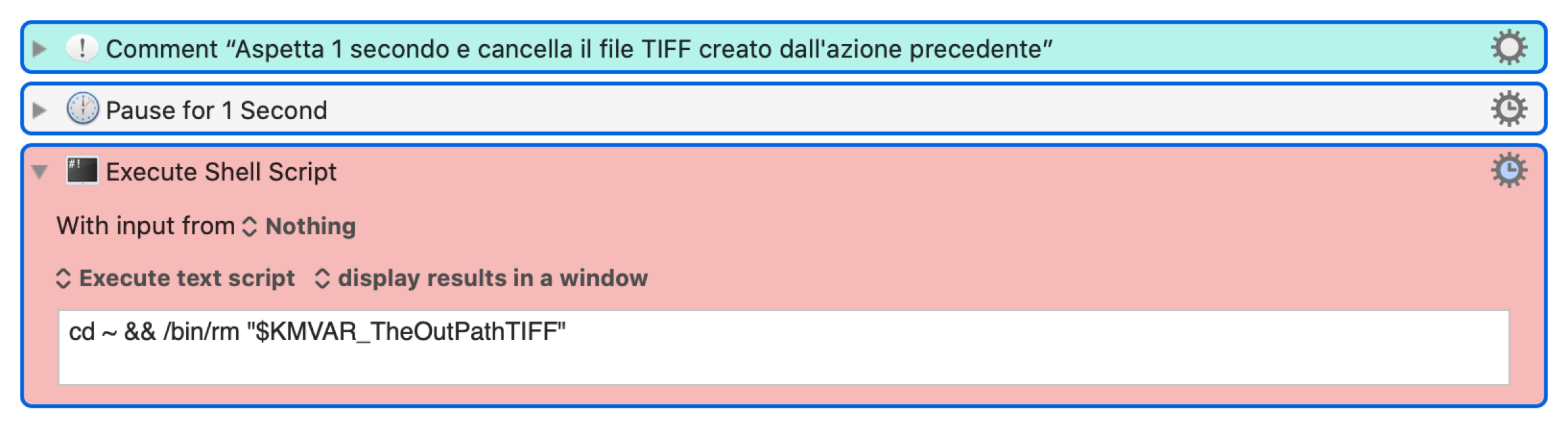
Serie di azioni per cancellare il TIFF intermedio
7. Breve video dimostrativo
Qui di seguito lascio un breve video su come funziona l’automazione (non avevo ancora implementato la cancellazione del file TIFF quando ho fatto la registrazione).
Materiale di riferimento
- Sito di sviluppo GitHub
- Tesseract su Wikipedia)
- Usa sips per convertire rapidamente, facilmente e liberamente i file di immagine – articolo in inglese
- Command line reference – Database and OS scripting: Sips
In conclusione
Credo che questo articolo sia l’esempio di come sia possibile “riciclare” il lavoro fatto per ulteriormente automatizzare.
Spero anche di aver incuriosito alcuni di voi nell’utilizzo dell’OCR in ambito professionale: personalmente è molto raro che un documento che archivio non sia reso indicizzabile con il riconoscimento ottico dei caratteri. Questo di permette di velocizzare di molta la ricerca dei documenti e utilizzarne il testo (copiandolo ed incollandolo dove mi serve) quando ne ho bisogno.
Come sempre se avete domande o richieste di chiarimenti potete lasciare un commento qui sotto.