Negli articoli precedenti abbiamo visto come datare un documento che abbiamo creato o acquisito.
Questo tipo di automazione, tuttavia è possibile solo quando la creazione o l'acquisizione viene svolta in un periodo poco distante dalla data "reale" del documento.
Come fare per un documento di un passato più remoto? Non sarebbe bello che il nostro Mac facesse il lavoro al posto nostro?
A determinate condizioni é possibile farlo attraverso Hazel. Questo articolo parla di funzioni avanzate di Hazel e potrebbe richiedere la rilettura.
1. Le condizioni per cui è possibile utilizzare Hazel per datare, nominare e spostare un documento
Di seguito spiegherò i principi di funzionamento del riconoscimento dei documenti di Hazel ed i suoi conseguenti limiti. Spostare un documento da una cartella all'altra è una funzione base di Hazel e non me ne occuperò in questo articolo, dandolo per scontato avendone già parlato qui.
1.1 Hazel e la possibilità di leggere il contenuto dei documenti testuali ed in particolare dei PDF
Nell'articolo introduttivo di Hazel vi indicavo che il programma possiede svariate regole attraverso le quali filtrare la ricerca di un documento.
Una delle regole meno scontate e più potenti è quella denominata"Contents" (Contenuti in italiano).
La regola va a leggere il contenuto del documento. Specificando poi l'ulteriore parametro "contain/do not contain" (contiene/non contiene in italiano) è possibile abbinare tutte le parole che la ricerca di Spotlight ha la capacità di indicizzare. In estrema sintesi, se è possibile trovare un determinato documento inserendo quella parola all'interno di una ricerca Spotlight allora è possibile anche con Hazel.
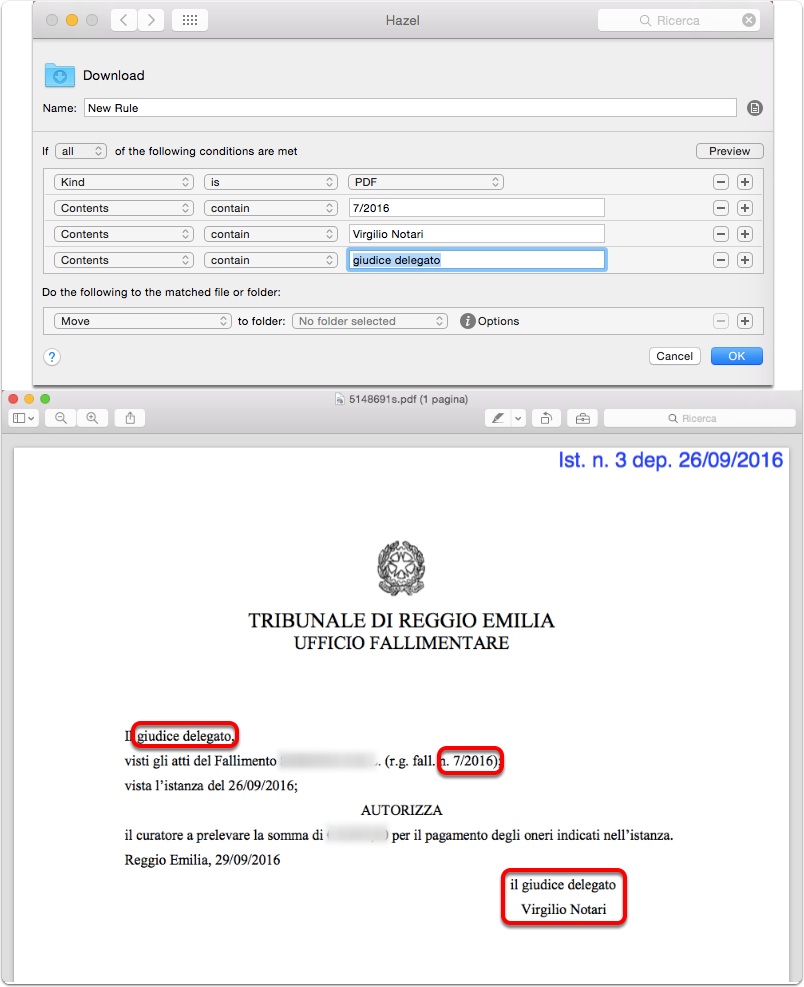
Se è utile avere una regola che abbina un documento a determinate parole chiave in esso contenute, è ancora più utile avere la possibilità di ricercare uno schema o un modello all'interno di un documento. Tale ricerca è possibile scegliendo l'opzione "contain match/do not contain match" (contiene il modello/non contiene il modello) e dando ad Hazel i parametri dello schema da ricercare all'interno del documento (vedete un esempio nell'immagine che segue, punto 2).
1.2 I PDF testuali e quelli sottoposti ad OCR: ovvero il riconoscimento automatico del testo
Come detto nel punto precedente, perchè Hazel possa fare una ricerca nei documenti, questi debbono essere indicizzati da Spotlight. I documenti ricercabili da Hazel debbono essere di testo (come i documenti .TXT, . RFT, .DOC etc ... ) e non immagini. Com'è possibile, quindi, ricercare documenti acquisiti con uno scanner?
OCR è l'acronimo di Optical Character Recognition ovvero Riconoscimento ottico dei caratteri. Esistono software che permettono di estrarre dalle scansioni il testo di un documento cartaceo. In futuri articoli vi parlerò di come trasformare le scansioni di immagini in documenti di testo ibridi (testo riconosciuto con il sistema di OCR su un livello ed immagine su di un altro).
Oggi vi sottolineo come la possibilità di leggere all'interno di un PDF dipende dalla fatto che questo sia stato originariamente creato da un file di testo o, nel caso di scansioni di documenti cartacei, gli sia stato applicato il Riconoscimento del testo.
1.3 La presenza di uno schema ripetitivo in più documenti
Per utilizzare Hazel per archiviare automaticamente i documenti occorre che questi ultimi siano "ripetitivi" ovvero con contenuti e caratteristiche simili. Come detto al punto 1 di questo sottocapitolo, dobbiamo dare un modello ad Hazel che gli permetta poi di eseguire le azioni. Se non abbiamo dei documenti "ripetitivi" o che comunque hanno un modello comune, non potremo usare Hazel in modo efficace.
A titolo di esempio i documenti devono contenere un medesimo gruppo di parole, la data dei documenti deve essere sempre nello stesso formato e così via.
1.4 Usare i dati reperiti per rinominare il documenti
Oltre a rilevare gli schemi all'interno di un documento Hazel è poi in grado di estrapolare questi schemi, ad esempio la data contenuta all'interno di un documento, ed usarle lo schema per rinominare il documento.
1.5 Una cartella per dominarle tutte ...
Ne ho parlato in altri articoli, ma voglio ripetermi perché è importante. Per un uso efficiente di questo sistema è opportuno salvare tutti i documenti che vogliamo far elaborare da Hazel in un'unica cartella recipiente. Io uso, con poca fantasia, una cartella denominata "scansioni". David Sparks, da cui ho imparato il trucco leggendo il suo libro Paperless, ha una cartella denominata, con più enfasi, Actions (Azioni).
2. Il caso pratico: l'archiviazione dei provvedimenti giudiziali scaricati da pst.giustizia.it o altro portale
Venendo quindi all'esempio su cui ragionare ho deciso di scegliere i provvedimenti di magistrati scaricabili dal portale del Ministero di Giustizia.
Questi documenti infatti vengono nominati con un codice numerico non intellegibile (ad esempio "5148691s.pdf") e sono documenti PDF testuali, quindi, di facile riconoscimento.
Vedete un esempio nell'immagine che segue; il documento è un PDF testuale, come si vede dalla selezione del testo, e contiene una data (non fate caso a PopClip l'applicazione che uso per fare alcune manipolazioni del testo).
Con Hazel è possibile datare e rinominare il documento oltre che archiviarlo nella cartella provvedimenti giudiziali della vostra pratica (di cui vi ho parlato qui). Occorrerà solo scaricare il provvedimento nella nostra cartella "scansioni".
Nella parte finale dell'articolo farò un'appendice su alcune premure per i documenti acquisiti digitalmente ed a cui è stato applicato l'OCR.
Pur essendo un esempio da "avvocati" è facile utilizzarlo per altri scopi. Infatti con questo metodo è possibile archiviare senza pensieri bollette o fatture ed altri documenti "ripetitivi".